目录
引言
一、环境准备
二、部署node-exporter
(一)创建命名空间
(二)部署node-exporter
1.获取镜像
2.定义yaml文件
3.创建服务
4.查看监控数据
三、部署Prometheus
(一)创建账号并授权
(二)创建configmap存储卷
(三)部署prometheus
(四)创建svc
(五)添加targets后的重启方法
1.热加载
2.删除后重建
四、部署Grafana
(一)准备镜像
(二)创建Grafana的pod资源
(三)创建Grafana的svc资源
(四)访问Grafana
1.登录grafana
2.配置grafana
3.导入监控模板
3.1 导入node的监控模板
3.2 导入监控容器状态模板
3.3 导入集群监控模板
五、部署kube-state-metrics
(一)部署kube-state-metrics
1.创建sa账号并授权
2.安装kube-state-metrics组件
3.创建service资源
(二)配置Grafana
1.配置k8s群集状态
1.1 获取模板
1.2 添加模板
2.配置kube-state-metrics
2.1 获取模板文件
2.2 添加模板文件
六、部署alertmanager
(一)Alertmanager的工作流程
(二)部署Alertmanager
1.创建alertmanager配置文件
2.创建prometheus和告警规则配置文件
3.安装prometheus和alertmanager
3.1 创建secret资源
3.2 创建资源清单
(三)部署alertmanager的service
(四)访问alertmanager
(五)处理kube-proxy监控告警
引言
在云原生时代,Kubernetes(简称K8s)已经成为了容器编排的事实标准。然而,如何监控这个庞大的集群,确保其稳定运行,是每个运维人员都需要面对的问题。Prometheus和Grafana作为开源的监控和可视化工具,被广泛应用于Kubernetes集群的监控中。本文将详细介绍如何在Kubernetes集群中部署Prometheus和Grafana,以实现对集群的全面监控。
一、环境准备
| 主机名 | IP地址 | 主机类型 | 资源配置 |
| master01 | 192.168.83.30 | 控制节点 | 4C4G |
| node01 | 192.168.83.40 | 工作节点1 | 4C4G |
| node02 | 192.168.83.50 | 工作节点2 | 4C4G |
二、部署node-exporter
(一)创建命名空间
创建监控namespace
[root@master01 ~]#kubectl create ns monitor-sa
namespace/monitor-sa created
[root@master01 ~]#kubectl get ns monitor-sa
NAME STATUS AGE
monitor-sa Active 9s
(二)部署node-exporter
1.获取镜像
docker pull的方式下载镜像,可以从hub.docker.com下载,或者使用国内的镜像替代
[root@master01 images]#ls node-exporter.tar
node-exporter.tar
[root@master01 images]#docker load -i node-exporter.tar
ad68498f8d86: Loading layer [==============================>] 4.628MB/4.628MB
ad8512dce2a7: Loading layer [==============================>] 2.781MB/2.781MB
cc1adb06ef21: Loading layer [==============================>] 16.9MB/16.9MB
Loaded image: prom/node-exporter:v0.16.0
'----------------------------------------------------------------------------'
[root@node01 images]#ls node-exporter.tar
node-exporter.tar
[root@node01 images]#docker load -i node-exporter.tar
ad68498f8d86: Loading layer [==============================>] 4.628MB/4.628MB
ad8512dce2a7: Loading layer [==============================>] 2.781MB/2.781MB
cc1adb06ef21: Loading layer [==============================>] 16.9MB/16.9MB
Loaded image: prom/node-exporter:v0.16.0
'----------------------------------------------------------------------------'
[root@node02 images]#ls node-exporter.tar
node-exporter.tar
[root@node02 images]#docker load -i node-exporter.tar
ad68498f8d86: Loading layer [==============================>] 4.628MB/4.628MB
ad8512dce2a7: Loading layer [==============================>] 2.781MB/2.781MB
cc1adb06ef21: Loading layer [==============================>] 16.9MB/16.9MB
Loaded image: prom/node-exporter:v0.16.0
[root@node02 images]#docker images|grep prom/node-exporter
prom/node-exporter v0.16.0 188af75e2de0 6 years ago 22.9MB2.定义yaml文件
使用yaml文件,以DaemonSet副本控制器,在每个节点上部署node-exporter
[root@master01 prometheus]#vim node-export.yaml
---
apiVersion: apps/v1
kind: DaemonSet #可以保证 k8s 集群的每个节点都运行完全一样的 pod
metadata:
name: node-exporter
namespace: monitor-sa
labels:
name: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true #允许Pod使用宿主机的 PID
hostIPC: true #允许Pod使用宿主机的IPC
hostNetwork: true #允许Pod使用宿主机的网络命名空间
containers:
- name: node-exporter
image: prom/node-exporter:v0.16.0 #指定镜像
ports:
- containerPort: 9100 #指定容器暴露端口
resources:
requests:
cpu: 0.15 #这个容器运行至少需要0.15核cpu
securityContext:
privileged: true #开启特权模式
args: #传递给容器的命令行参数
- --path.procfs
- /host/proc
#通知node-exporter在哪里找到宿主机的/proc文件系统。
#由于node-exporter运行在容器中,不能直接访问宿主机的/proc文件系统,需要通过挂载来访问它
- --path.sysfs
- /host/sys
#类似地,这个参数告诉node-exporter在哪里找到宿主机的/sys文件系统
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
#这个参数指定以sys等开头文件系统挂载点,被node-exporter的文件系统收集器忽略,
volumeMounts: #定义了容器内挂载卷的路径
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
#定义了DaemonSet容忍了标记为node-role.kubernetes.io/master的节点上的污点
volumes: #定义了 Pod 中要使用的卷
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /3.创建服务

[root@master01 prometheus]#kubectl apply -f node-export.yaml
daemonset.apps/node-exporter created
[root@master01 prometheus]#kubectl get pod -n monitor-sa -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-dvl2v 1/1 Running 0 24s 192.168.83.30 master01 <none> <none>
node-exporter-nhk4t 1/1 Running 0 24s 192.168.83.40 node01 <none> <none>
node-exporter-rs8pd 1/1 Running 0 24s 192.168.83.50 node02 <none> <none>4.查看监控数据
node-exporter 默认的监听端口是 9100,可以执行 curl http://主机ip:9100/metrics 获取到主机的所有监控数据
比如查看cpu的数据
curl -Ls http://192.168.83.30:9100/metrics | grep node_cpu_seconds
[root@master01 prometheus]#curl -Ls http://192.168.83.30:9100/metrics | grep node_cpu_seconds
# HELP node_cpu_seconds_total Seconds the cpus spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 6110.13
node_cpu_seconds_total{cpu="0",mode="iowait"} 5.72
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 0.05
node_cpu_seconds_total{cpu="0",mode="softirq"} 33.77
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 175.56
node_cpu_seconds_total{cpu="0",mode="user"} 164.87
node_cpu_seconds_total{cpu="1",mode="idle"} 6129.08
node_cpu_seconds_total{cpu="1",mode="iowait"} 4.52
node_cpu_seconds_total{cpu="1",mode="irq"} 0
node_cpu_seconds_total{cpu="1",mode="nice"} 0.05
node_cpu_seconds_total{cpu="1",mode="softirq"} 28.48
node_cpu_seconds_total{cpu="1",mode="steal"} 0
node_cpu_seconds_total{cpu="1",mode="system"} 181.28
node_cpu_seconds_total{cpu="1",mode="user"} 163.54
node_cpu_seconds_total{cpu="2",mode="idle"} 6126.05
node_cpu_seconds_total{cpu="2",mode="iowait"} 4.47
node_cpu_seconds_total{cpu="2",mode="irq"} 0
node_cpu_seconds_total{cpu="2",mode="nice"} 0
node_cpu_seconds_total{cpu="2",mode="softirq"} 38.63
node_cpu_seconds_total{cpu="2",mode="steal"} 0
node_cpu_seconds_total{cpu="2",mode="system"} 175.99
node_cpu_seconds_total{cpu="2",mode="user"} 166.63
node_cpu_seconds_total{cpu="3",mode="idle"} 6132.87
node_cpu_seconds_total{cpu="3",mode="iowait"} 2.5
node_cpu_seconds_total{cpu="3",mode="irq"} 0
node_cpu_seconds_total{cpu="3",mode="nice"} 0
node_cpu_seconds_total{cpu="3",mode="softirq"} 29.81
node_cpu_seconds_total{cpu="3",mode="steal"} 0
node_cpu_seconds_total{cpu="3",mode="system"} 183.06
node_cpu_seconds_total{cpu="3",mode="user"} 167.03
三、部署Prometheus
(一)创建账号并授权
创建一个管理账号,并绑定admin用户,admin用户拥有所有资源的所有权限
[root@master01 prometheus]#kubectl create serviceaccount monitor -n monitor-sa
serviceaccount/monitor created
[root@master01 prometheus]#kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
clusterrolebinding.rbac.authorization.k8s.io/monitor-clusterrolebinding created
#指定管理的命名空间(二)创建configmap存储卷
在ConfigMap中,需要定义Prometheus的全局配置以及数据采集规则。数据采集规则包括从Kubernetes API Server、node-exporter等组件中收集指标数据的规则
[root@master01 prometheus]#cat prometheus-cfg.yaml
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitor-sa
data:
prometheus.yml: | #Prometheus 配置文件的内容
#-----------------------------全局设置-------------------------------------------
global: #指定prometheus的全局配置,比如采集间隔,抓取超时时间等
scrape_interval: 15s #采集目标主机监控数据的时间间隔,默认为1m
scrape_timeout: 10s #数据采集超时时间,默认10s
evaluation_interval: 1m #触发告警生成alert的时间间隔,默认是1m
scrape_configs: #配置数据源,称为target,每个target用job_name命名。
#-------------------第一个服务发现:监控 Kubernetes 集群中的节点------------------------
- job_name: 'kubernetes-node'
kubernetes_sd_configs: #指定的是k8s的服务发现
- role: node #使用node角色,它使用默认的kubelet提供的http端口来发现集群中每个node节点
relabel_configs: #重新标记,修改目标地址
- source_labels: [__address__] #配置的原始标签,匹配地址
regex: '(.*):10250' #匹配带有10250端口的url
replacement: '${1}:9100' #把匹配到的ip:10250的ip保留,类似与sed的后向引用
target_label: __address__ #新生成的url是${1}获取到的ip:9100
action: replace
#动作替换,从默认的kubelet端口(10250)更改为Prometheus Node Exporter 的端口(9100)
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) #匹配到下面正则表达式的标签会被保留,如果不做regex正则的话,默认只是会显示instance标签
#--------------第二个服务发现:监控 Kubernetes 集群中每个节点的 cAdvisor-----------------
#抓取cAdvisor数据,是获取kubelet上/metrics/cadvisor接口数据来获取容器的资源使用情况
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https #定义了与cAdvisor服务通信时使用HTTPS协议
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #CA证书文件的路径
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #指定了包含用于与Kubernetes API服务器进行身份验证的Bearer令牌的文件路径
relabel_configs:
- action: labelmap #把匹配到的标签保留
regex: __meta_kubernetes_node_label_(.+) #保留匹配到的具有__meta_kubernetes_node_label的标签
- target_label: __address__ #获取到的地址:__address__="192.168.80.20:10250"
replacement: kubernetes.default.svc:443 #把获取到的地址替换成新的地址kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+) #把原始标签中__meta_kubernetes_node_name值匹配到
target_label: __metrics_path__ #获取__metrics_path__对应的值
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
#把metrics替换成新的值api/v1/nodes/k8s-master1/proxy/metrics/cadvisor
#${1}是__meta_kubernetes_node_name获取到的值
#新的url就是https://kubernetes.default.svc:443/api/v1/nodes/k8s-master1/proxy/metrics/cadvisor
#------------------第三个服务发现:监控Kubernetes API服务器---------------------------
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints #使用k8s中的endpoint服务发现,采集apiserver6443端口获取到的数据
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
#[endpoint这个对象的名称空间,endpoint对象的服务名,exnpoint的端口名称]
action: keep #采集满足条件的实例,其他实例不采集
regex: default;kubernetes;https #正则匹配到的默认空间下的service名字是kubernetes,协议是https的endpoint类型保留下来
#-----------------------------第四个服务发现--------------------------------------
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
#重新打标仅抓取到的具有"prometheus.io/scrape: true"的annotation的端点
#意思是说如果某个service具有prometheus.io/scrape = true的annotation声明则抓取
#annotation本身也是键值结构, 所以这里的源标签设置为键
#而regex设置值true,当值匹配到regex设定的内容时则执行keep动作也就是保留,其余则丢弃。
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
#重新设置scheme,匹配源标签__meta_kubernetes_service_annotation_prometheus_io_scheme
#也就是prometheus.io/scheme annotation
#如果源标签的值匹配到regex,则把值替换为__scheme__对应的值。
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
#应用中自定义暴露的指标,也许你暴露的API接口不是/metrics这个路径,
#那么你可以在这个POD对应的service中做一个 "prometheus.io/path = /mymetrics" 声明,
#上面的意思就是把你声明的这个路径赋值给__metrics_path__,
#其实就是让prometheus来获取自定义应用暴露的metrices的具体路径,
#不过这里写的要和service中做好约定,
#如果service中这样写 prometheus.io/app-metrics-path: '/metrics'
#那么这里写__meta_kubernetes_service_annotation_prometheus_io_app_metrics_path
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
#暴露自定义的应用的端口,就是把地址和你在service中定义的 "prometheus.io/port = <port>"
#声明做一个拼接, 然后赋值给__address__,这样prometheus就能获取自定义应用的端口,
#然后通过这个端口再结合__metrics_path__来获取指标,
#如果__metrics_path__值不是默认的/metrics那么就要使用上面的标签替换来获取真正暴露的具体路径
- action: labelmap #保留下面匹配到的标签
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace #替换__meta_kubernetes_namespace变成kubernetes_namespace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name创建服务
[root@master01 prometheus]#kubectl apply -f prometheus-cfg.yaml
configmap/prometheus-config created
[root@master01 prometheus]#kubectl get configmaps -n monitor-sa
NAME DATA AGE
kube-root-ca.crt 1 26h
prometheus-config 1 77s(三)部署prometheus
通过 deployment 部署prometheus
将 prometheus 调度到node1节点,在 node1 节点创建 prometheus 数据存储目录
首先在节点上预加载镜像,防止因为网络问题,导致镜像加载失败
或者可以使用国内的镜像代替
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/prometheus:v2.30.3
[root@node01 images]#ls prometheus.tar
prometheus.tar
[root@node01 images]#docker load -i prometheus.tar
6a749002dd6a: Loading layer [==================================================>] 1.338MB/1.338MB
5f70bf18a086: Loading layer [==================================================>] 1.024kB/1.024kB
1692ded805c8: Loading layer [==================================================>] 2.629MB/2.629MB
035489d93827: Loading layer [==================================================>] 66.18MB/66.18MB
8b6ef3a2ab2c: Loading layer [==================================================>] 44.5MB/44.5MB
ff98586f6325: Loading layer [==================================================>] 3.584kB/3.584kB
017a13aba9f4: Loading layer [==================================================>] 12.8kB/12.8kB
4d04d79bb1a5: Loading layer [==================================================>] 27.65kB/27.65kB
75f6c078fa6b: Loading layer [==================================================>] 10.75kB/10.75kB
5e8313e8e2ba: Loading layer [==================================================>] 6.144kB/6.144kB
Loaded image: prom/prometheus:v2.2.1
定义yaml文件
[root@master01 prometheus]#vim prometheus-deploy.yaml
[root@master01 prometheus]#cat prometheus-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server #部署的名称
namespace: monitor-sa #指定命名空间
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false' #Pod的注解,表示Prometheus不从此端点抓取数据
spec:
nodeName: node01 #指定Pod应调度到的节点名称
serviceAccountName: monitor #指定Pod使用的ServiceAccount的名称
containers:
- name: prometheus
image: prom/prometheus:v2.2.1 #要使用的容器镜像和标签
imagePullPolicy: IfNotPresent
command:
- prometheus #启动命令
- --config.file=/etc/prometheus/prometheus.yml #指定加载的配置文件
- --storage.tsdb.path=/prometheus #数据存储目录
- --storage.tsdb.retention=720h #数据保存时长
- --web.enable-lifecycle #开启热加载
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus/prometheus.yml
name: prometheus-config
subPath: prometheus.yml
- mountPath: /prometheus/
name: prometheus-storage-volume
volumes:
- name: prometheus-config
configMap: #指定挂载的configMap资源
name: prometheus-config
items:
- key: prometheus.yml
path: prometheus.yml
mode: 0644
- name: prometheus-storage-volume
hostPath:
path: /data
type: Directory在node01节点创建挂载目录
[root@node01 ~]#mkdir /data && chmod 777 /data创建服务
[root@master01 prometheus]#kubectl apply -f prometheus-deploy.yaml
deployment.apps/prometheus-server created
[root@master01 prometheus]#kubectl get pod prometheus-server-75fb7f8fc6-smgjl -o wide -n monitor-sa
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
prometheus-server-75fb7f8fc6-smgjl 1/1 Running 5 21s 10.244.1.56 node01 <none> <none>
进入pod查看配置文件
[root@master01 prometheus]#kubectl exec -it prometheus-server-75fb7f8fc6-smgjl -n monitor-sa sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
/prometheus $ cat /etc/prometheus/prometheus.yml
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
......(四)创建svc
[root@master01 prometheus]#vim prometheus-svc.yaml
[root@master01 prometheus]#cat prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor-sa
labels:
app: prometheus
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
protocol: TCP
nodePort: 31000
selector:
app: prometheus
component: server
[root@master01 prometheus]#kubectl apply -f prometheus-svc.yaml
service/prometheus created
[root@master01 prometheus]#kubectl get svc -n monitor-sa
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.96.218.105 <none> 9090:31000/TCP 3s
使用web浏览器访问节点的31000端口

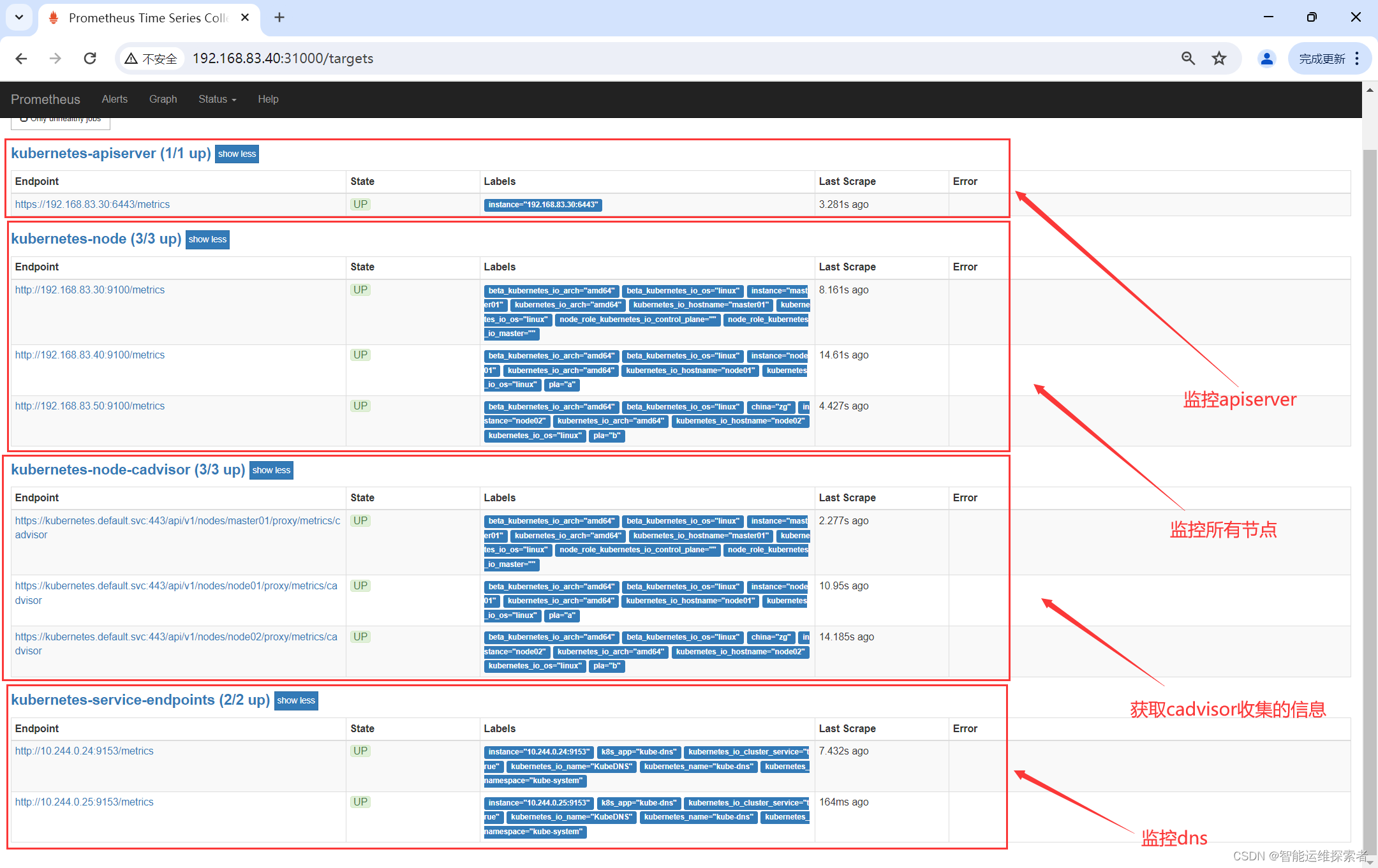
监控apiserver
确保集群健康:apiserver是Kubernetes集群的核心组件,负责处理所有与集群相关的API请求。通过Prometheus监控apiserver,可以实时获取其性能指标,如请求延迟、错误率等,从而确保集群的健康状态。
服务发现:Prometheus支持基于Kubernetes服务发现(Service Discovery)的自动配置,可以自动发现apiserver作为监控目标,无需手动配置。
问题诊断:一旦apiserver出现性能问题或故障,Prometheus可以提供详细的历史数据和告警信息,帮助管理员快速定位问题并进行处理。
监控nodes
资源利用率:Prometheus可以监控节点(nodes)的资源利用率,包括CPU、内存、磁盘等,从而评估集群的负载情况和扩展需求。
节点状态:通过监控节点的状态信息,可以及时发现节点故障或异常情况,并采取相应的措施进行处理,避免影响集群的整体稳定性。
监控cAdvisor
容器性能:cAdvisor是Kubernetes中的一个组件,用于收集容器性能数据。Prometheus可以集成cAdvisor,实时获取容器的CPU、内存、网络等性能指标,从而了解容器的运行状况。
资源优化:通过监控容器性能数据,管理员可以分析资源使用情况,优化容器的资源配置,提高资源利用率和集群的整体性能。
监控kube-dns
服务发现:kube-dns是Kubernetes集群中的DNS服务器,负责为服务提供DNS解析。通过Prometheus监控kube-dns,可以确保其稳定运行,从而保障服务发现功能的正常使用。
性能监控:Prometheus可以监控kube-dns的性能数据,如查询延迟、缓存命中率等,从而评估其性能状态并采取相应的优化措施
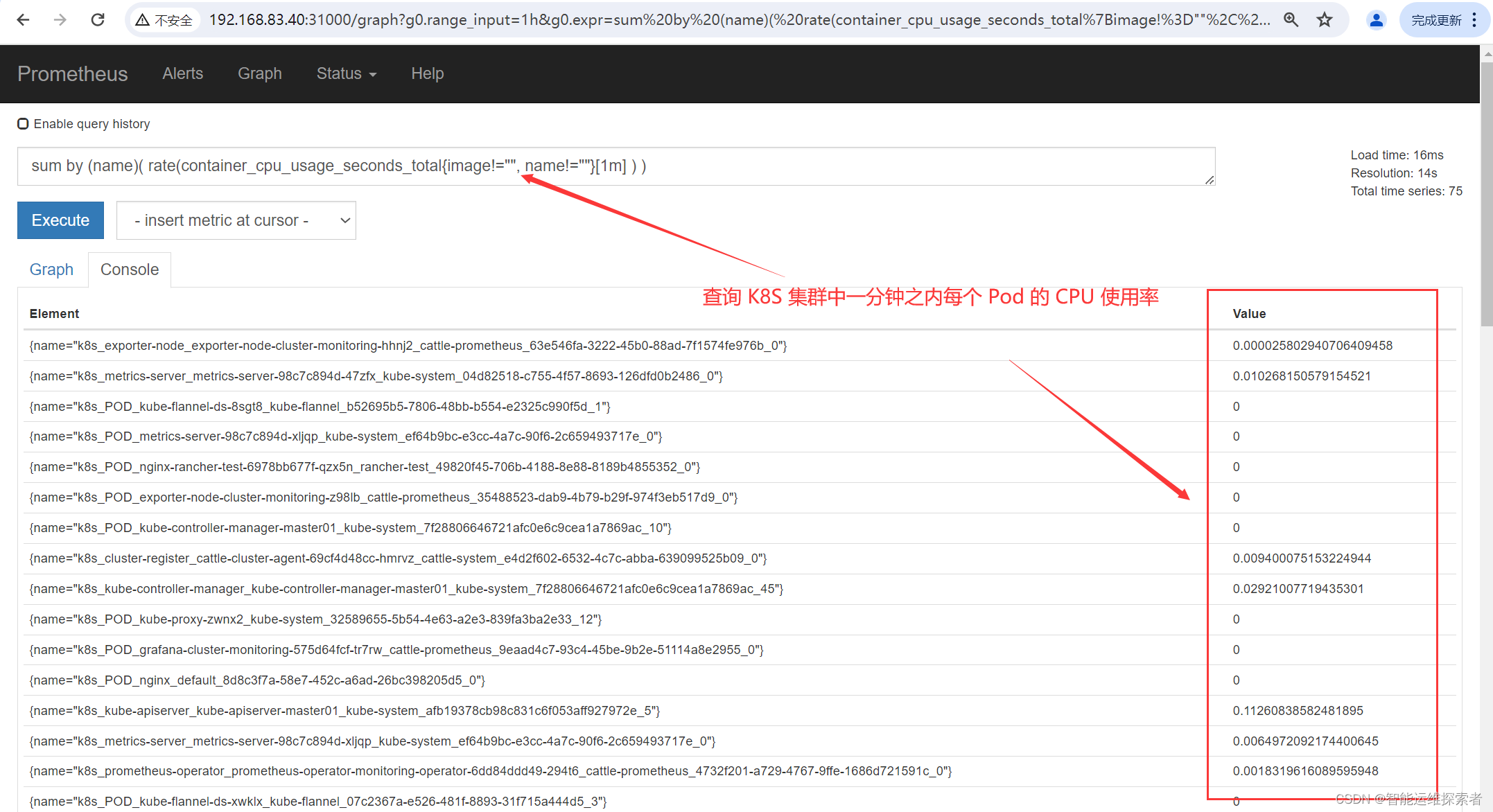
查询每一分钟每个pod的CPU使用率
sum by (name)( rate(container_cpu_usage_seconds_total{image!="", name!=""}[1m] ) )
container_cpu_usage_seconds_total
这是一个由cAdvisor暴露的metrics,它表示容器使用的CPU秒数。这是一个累积计数器,意味着它的值会随着时间的推移而增加。
{image!="", name!=""}
这是一个标签选择器(label selector),它用于过滤出那些image和name标签都不为空(即存在)的metrics。这通常是为了避免监控那些没有具体名称或镜像的容器(可能是系统或临时容器)。
[1m]
这是一个时间窗口选择器,表示选择过去1分钟的数据。这通常用于与rate函数结合,以计算每秒的速率。
rate(...)
rate函数用于计算计数器在给定时间窗口内的平均每秒增长率。在这个例子中,它计算了container_cpu_usage_seconds_total在过去1分钟内的平均每秒CPU使用率。
sum by (name)
sum by是一个聚合操作符,它会对指定的标签进行分组,并对每个组内的值进行求和。这意味着你会得到一个结果列表,其中每个结果都代表一个具有特定name标签的容器的CPU使用率总和(以每秒CPU秒数为单位)
(五)添加targets后的重启方法
1.热加载
每次修改配置文件可以热加载prometheus,也就是不停止prometheus,就可以使配置生效
curl -X POST -Ls http://Prometheus-IP/-/reload
2.删除后重建
修改完yaml文件后,使用kubectl delete删除之后再重新创建
kubectl delete -f prometheus-cfg.yaml
kubectl delete -f prometheus-deploy.yaml
kubectl apply -f prometheus-cfg.yaml
kubectl apply -f prometheus-deploy.yaml
注释:项目上线后最好使用热加载的方式,避免监控数据丢失
四、部署Grafana
(一)准备镜像
同样的,在节点上预加载镜像,防止因为网络问题,导致镜像加载失败
[root@node01 images]#docker load -i grafana.tar
8fad67424c4e: Loading layer [=============================>] 129.3MB/129.3MB
5f70bf18a086: Loading layer [=============================>] 1.024kB/1.024kB
07ea00da69ad: Loading layer [=============================>] 179.7MB/179.7MB
2fd837eb56b5: Loading layer [=============================>] 3.584kB/3.584kB
Loaded image: grafana/grafana:5.0.4或者使用docker pull直接下载
[root@node01 ~]#docker pull grafana/grafana:7.1.5
7.1.5: Pulling from grafana/grafana
Digest: sha256:579044d31fad95f015c78dff8db25c85e2e0f5fdf37f414ce850eb045dd47265
Status: Downloaded newer image for grafana/grafana:7.1.5
docker.io/grafana/grafana:7.1.5(二)创建Grafana的pod资源
[root@master01 prometheus]#cat grafana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:5.0.4
ports:
- containerPort: 3000
protocol: TCP
volumeMounts: #定义了如何挂载卷到容器中
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var/lib/grafana/
name: grafana-storage
env: #定义容器内的环境变量
- name: INFLUXDB_HOST
value: monitoring-influxdb
#指定了Grafana连接到的InfluxDB数据库的主机名或IP地址
- name: GF_SERVER_HTTP_PORT
value: "3000"
#指定了Grafana HTTP服务器监听的端口
- name: GF_AUTH_BASIC_ENABLED
value: "false"
#用于启用或禁用Grafana的基本认证,false表示禁用
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
#用于启用或禁用Grafana的匿名访问,true表示启用
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
#当匿名访问被启用时,这个环境变量定义了匿名用户所拥有的组织角色,Admin表示具有管理员权限
- name: GF_SERVER_ROOT_URL
value: /
#定义了Grafana服务器的根URL
volumes: #定义了要挂载到Pod中的卷
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
创建资源
[root@master01 prometheus]#kubectl apply -f grafana.yaml
deployment.apps/monitoring-grafana created
[root@master01 prometheus]#kubectl get pod monitoring-grafana-5ccc887d98-ldbb4 -n kube-system
NAME READY STATUS RESTARTS AGE
monitoring-grafana-5ccc887d98-ldbb4 1/1 Running 0 7s
(三)创建Grafana的svc资源
[root@master01 prometheus]#vim grafana-service.yaml
[root@master01 prometheus]#cat grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: kube-system
spec:
ports:
- port: 80
targetPort: 3000
selector:
k8s-app: grafana
type: NodePort
[root@master01 prometheus]#kubectl apply -f grafana-service.yaml
service/monitoring-grafana created
[root@master01 prometheus]#kubectl get svc monitoring-grafana -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
monitoring-grafana NodePort 10.96.32.173 <none> 80:32071/TCP 66s
(四)访问Grafana
1.登录grafana
浏览器访问http://192.168.83.40:32071,登陆 grafana

2.配置grafana
【Name】设置成 Prometheus
【Type】选择 Prometheus
【URL】设置成 http://10.96.218.105:9090#使用service的集群内部端口配置服务端地址,kubectl get svc -n monitor-sa查看
点击 【Save & Test】

3.导入监控模板
官方链接:https://grafana.com/dashboards?dataSource=prometheus&search=kubernetes
选择适合的面板,点击 Copy ID 或者 Download JSON
3.1 导入node的监控模板
3.1.1 获取监控模板
下载json文件

3.2.2 导入模板
监控 node 状态
点击左侧+号选择【Import】
点击【Upload .json File】导入下载的模板文件
【Prometheus】选择 Prometheus
点击【Import】


3.2 导入监控容器状态模板
3.2.1 获取模板

点击左侧+号选择【Import】
点击【Upload .json File】导入下载的模板文件
【Prometheus】选择 Prometheus
点击【Import】

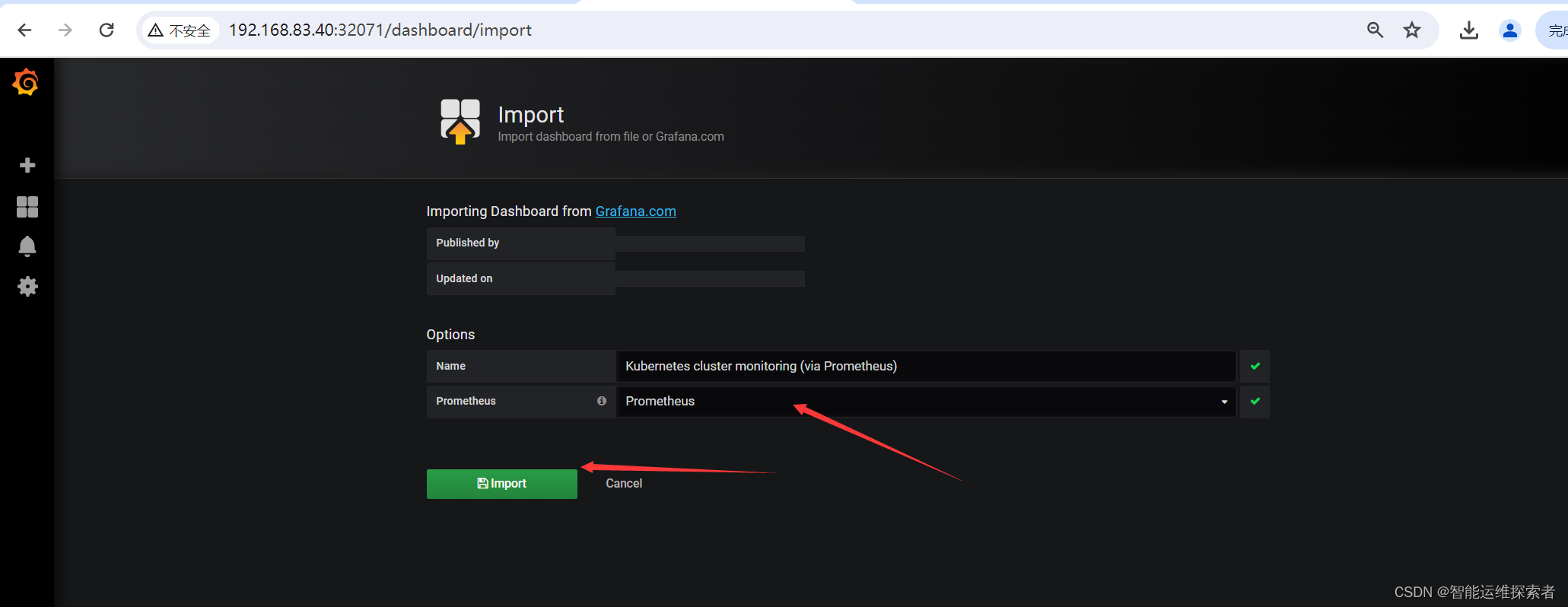
3.3 导入集群监控模板
3.3.1 获取模板
点击左侧+号选择【Import】
点击【Upload .json File】导入下载的模板文件
【Prometheus】选择 Prometheus
点击【Import】

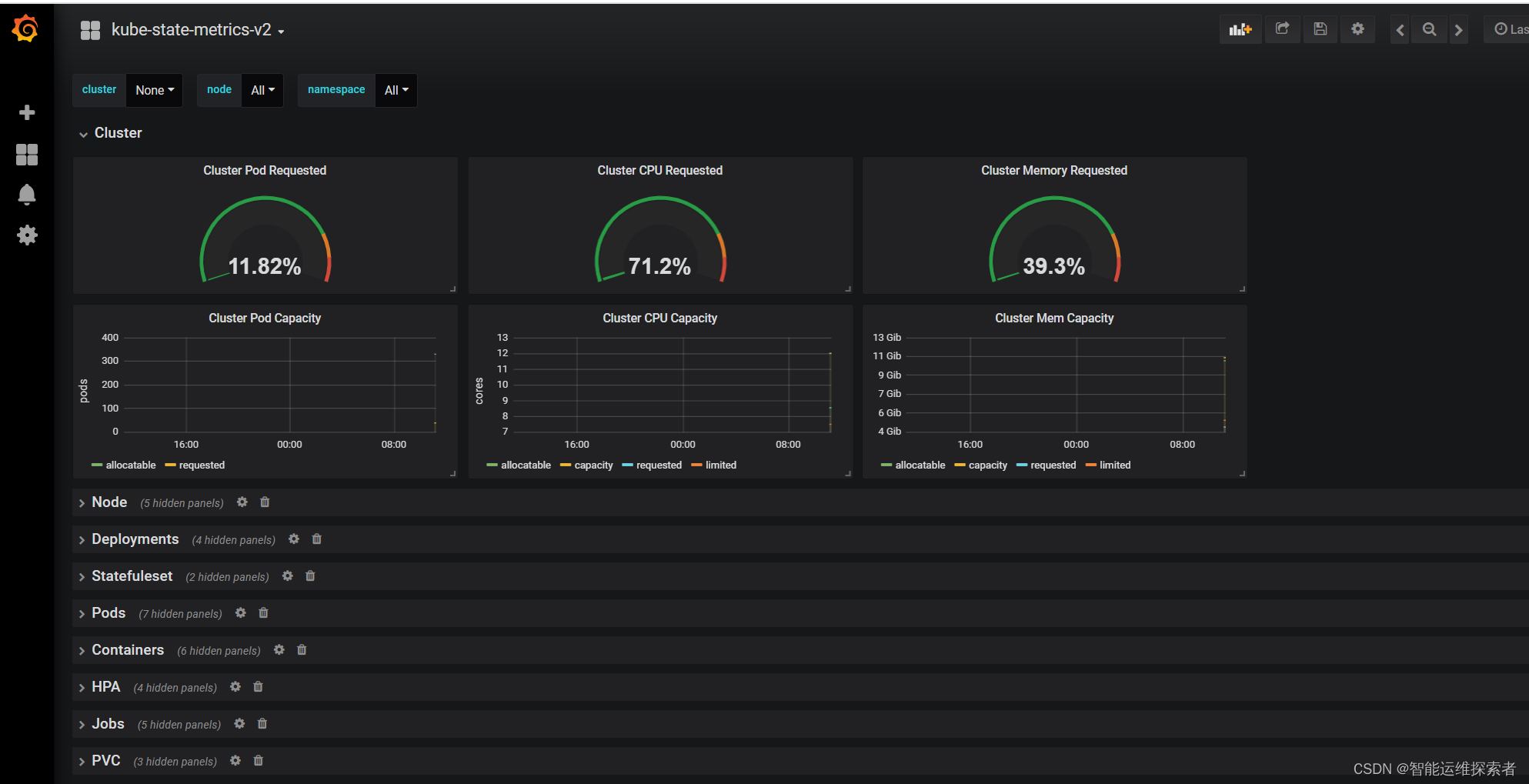
五、部署kube-state-metrics
kube-state-metrics是一个Kubernetes集群中的重要组件,它的主要作用是收集和暴露Kubernetes资源的状态指标,以便于监控和分析。具体来说,kube-state-metrics的功能可以概括为以下几点:
1.指标收集
kube-state-metrics定期查询Kubernetes API Server,获取集群中各种资源的最新状态,如Pods、Deployments、ReplicaSets、StatefulSets、Jobs、CronJobs、Services、Nodes、DaemonSets、PersistentVolumes、PersistentVolumeClaims、ReplicationControllers等,并将这些信息转换为Prometheus监控系统的指标格式。2.Prometheus兼容性
收集到的指标是以Prometheus监控系统可以解析的格式输出的,这意味着kube-state-metrics充当了一个Prometheus exporter的角色。Prometheus server可以定期抓取这些指标,进行存储和分析。3.资源状态可视化
除了被Prometheus抓取之外,kube-state-metrics也可以直接通过HTTP服务器暴露这些指标,便于其他监控工具或前端仪表板(如Grafana)可视化展示资源状态。4.异常统计
kube-state-metrics还提供了一些关于自身运行状况的指标,比如资源查询失败的次数,这对于监控kube-state-metrics自身的健康状况很有帮助。资源数量统计:
它还统计并报告各种Kubernetes资源的实例数量,这对于容量规划和资源管理非常有用。5.事件与状态
kube-state-metrics能够捕获Kubernetes资源的事件和状态变化,如Pod的启动、终止、重启次数,Deployment的滚动更新状态,以及Job的运行情况等
(一)部署kube-state-metrics
1.创建sa账号并授权
创建serviceaccount用户账号,并授予指定组的权限,使其对k8s资源有管理的权限,能够收集到资源信息
[root@master01 prometheus]#vim kube-state-metrics-rbac.yaml
[root@master01 prometheus]#cat kube-state-metrics-rbac.yaml
#创建账号
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-system
---
#创建集群角色,并指定角色权限
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources: ["daemonsets", "deployments", "replicasets"]
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources: ["cronjobs", "jobs"]
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources: ["horizontalpodautoscalers"]
verbs: ["list", "watch"]
---
#对用户与集群角色进行绑定,使创建的用户有一定的权限去管理,并获取资源信息
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
创建并查看信息
[root@master01 prometheus]#kubectl apply -f kube-state-metrics-rbac.yaml
serviceaccount/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
[root@master01 prometheus]#kubectl get sa kube-state-metrics -n kube-system
NAME SECRETS AGE
kube-state-metrics 1 42s
[root@master01 prometheus]#kubectl get clusterrolebindings kube-state-metrics -n kube-system
NAME ROLE AGE
kube-state-metrics ClusterRole/kube-state-metrics 58s
2.安装kube-state-metrics组件
2.1 获取镜像
[root@node01 images]#docker load -i kube-state-metrics.tar
932da5156413: Loading layer [================================>] 3.062MB/3.062MB
bd8df7c22fdb: Loading layer [================================>] 31MB/31MB
Loaded image: quay.io/coreos/kube-state-metrics:v1.9.0
或者使用docker pull下载
docker pull quay.io/coreos/kube-state-metrics
2.2 创建服务
[root@master01 prometheus]#vim kube-state-metrics-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: quay.io/coreos/kube-state-metrics:v1.9.0
ports:
- containerPort: 8080
[root@master01 prometheus]#kubectl get pod kube-state-metrics-58d4957bc5-m94fv -o wide -n kube-system
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-state-metrics-58d4957bc5-m94fv 1/1 Running 0 24s 10.244.1.59 node01 <none> <none>
3.创建service资源
[root@master01 prometheus]#vim kube-state-metrics-svc.yaml
[root@master01 prometheus]#cat kube-state-metrics-svc.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true' #注解信息,表示从此端点抓取数据
name: kube-state-metrics
namespace: kube-system
labels:
app: kube-state-metrics
spec:
ports:
- name: kube-state-metrics
port: 8080
protocol: TCP
selector:
app: kube-state-metrics
[root@master01 prometheus]#kubectl apply -f kube-state-metrics-svc.yaml
service/kube-state-metrics created
[root@master01 prometheus]#kubectl get svc kube-state-metrics -o wide -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kube-state-metrics ClusterIP 10.96.80.21 <none> 8080/TCP 16s app=kube-state-metrics(二)配置Grafana
1.配置k8s群集状态
配置k8s群集状态的监控信息
1.1 获取模板
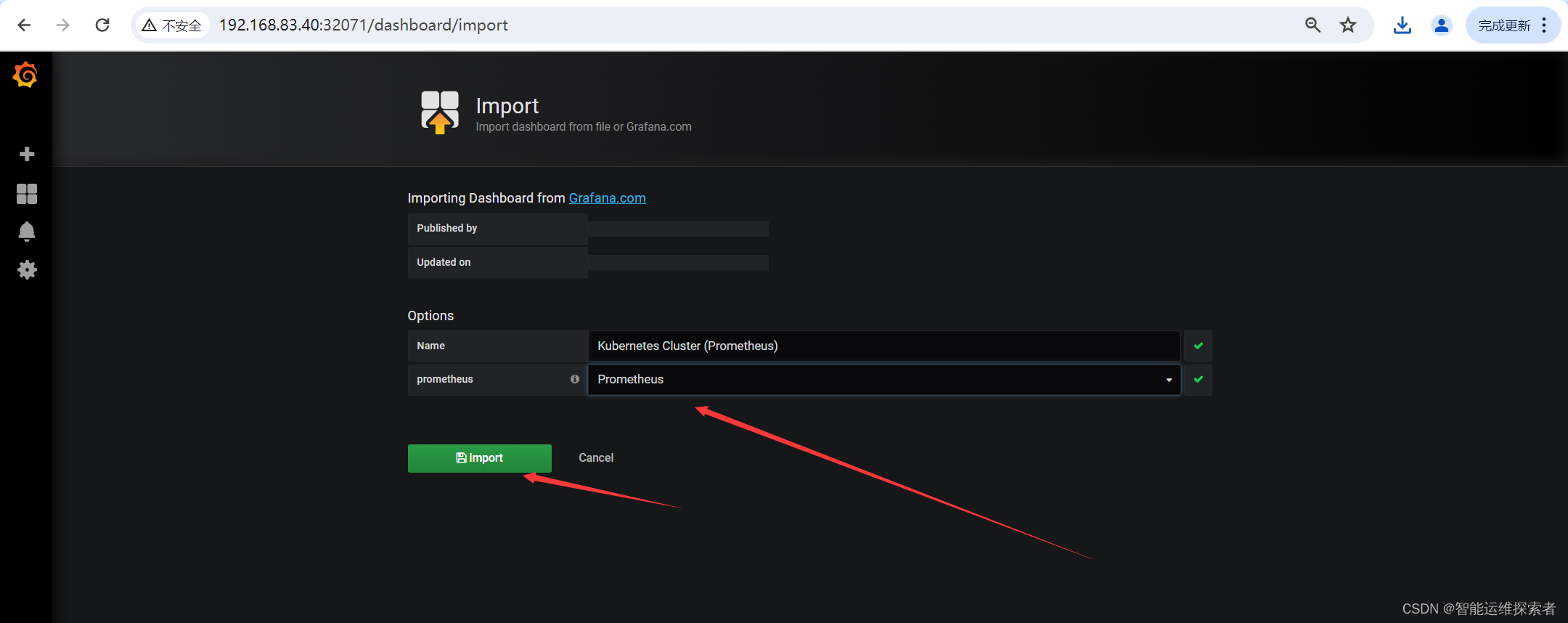
1.2 添加模板
点击左侧+号选择【Import】
点击【Upload .json File】导入下载的模板文件
【Prometheus】选择 Prometheus
点击【Import】

2.配置kube-state-metrics
2.1 获取模板文件

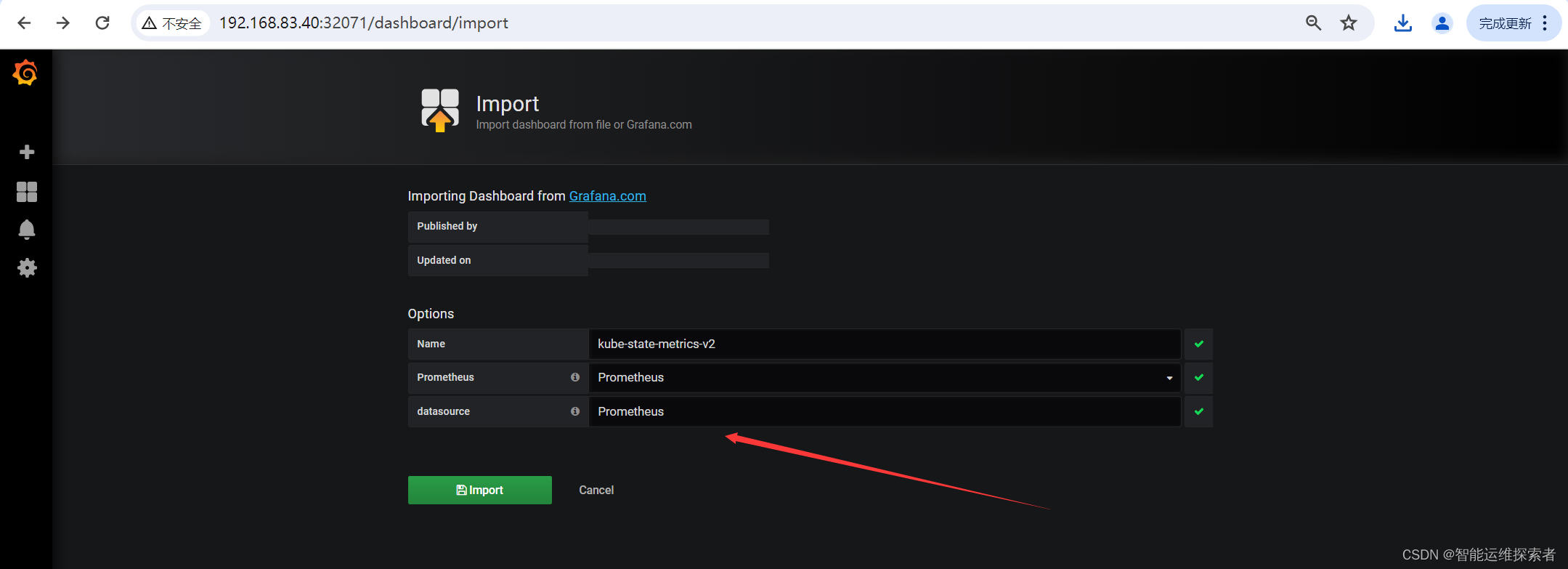
2.2 添加模板文件
点击左侧+号选择【Import】
点击【Upload .json File】导入下载的模板文件
【Prometheus】选择 Prometheus
点击【Import】
六、部署alertmanager
Alertmanager是一个开源的告警管理工具,主要用于处理来自于监控系统(如Prometheus)的告警。其设计目标是提供一个统一的告警处理平台,能够集中管理告警的路由、去重、分组和通知等操作。在现代云服务架构中,Alertmanager扮演着至关重要的角色,确保关键系统和服务的可靠性和稳定性
具体来说,Alertmanager的作用包括:
- 接收告警数据:从Prometheus等客户端接收告警信息。
- 告警处理:对接收到的告警信息进行去重、降噪、分组等处理,确保告警的及时性和准确性。
- 告警通知:根据路由规则将告警信息分发给指定的接收渠道,如邮件、Slack、Webhook等,支持多种通知方式。
- 告警优化:提供静默和告警抑制机制,对告警通知行为进行优化。
(一)Alertmanager的工作流程
Prometheus报警处理流程
1)Prometheus Server 监控目标主机上暴露的 http接口(假设接口A),通过Promethes配置的'scrape_interval' 定义的时间间隔, 定期采集目标主机上监控数据。2)当接口A不可用的时候,Server 端会持续的尝试从接口中取数据,直到 "scrape_timeout" 时间后停止尝试。 这时候把接口的状态变为 "DOWN"。
3)Prometheus 同时根据配置的 evaluation_interval 的时间间隔,定期(默认1min)的对 Alert Rule 进行评估; 当到达评估周期的时候,发现接口A为 DOWN,即 UP=0 为真,激活 Alert,进入 PENDING 状态,并记录当前 active 的时间;
4)当下一个 alert rule 的评估周期到来的时候,发现 UP=0 继续为真,然后判断警报 Active 的时间是否已经超出 rule 里的 for 持续时间,如果未超出,则进入下一个评估周期;如果时间超出,则 alert 的状态变为 FIRING;同时调用 Alertmanager 接口, 发送相关报警数据。
5)AlertManager 收到报警数据后,会将警报信息进行分组,然后根据 alertmanager 配置的 group_wait 时间先进行等待。等 wait 时间过后再发送报警信息。
6)属于同一个 Alert Group的警报,在等待的过程中可能进入新的 alert,如果之前的报警已经成功发出,那么间隔 group_interval 的时间间隔后再重新发送报警信息。比如配置的是邮件报警,那么同属一个 group 的报警信息会汇总在一个邮件里进行发送。
7)如果 Alert Group里的警报一直没发生变化并且已经成功发送,等待 repeat_interval 时间间隔之后再重复发送相同的报警邮件; 如果之前的警报没有成功发送,则相当于触发第6条条件,则需要等待 group_interval 时间间隔后重复发送。
8)同时最后至于警报信息具体发给谁,满足什么样的条件下指定警报接收人,设置不同报警发送频率,这里使用 alertmanager 的 route 路由规则进行配置。
(二)部署Alertmanager
1.创建alertmanager配置文件
以ConfigMap的形式,创建alertmanager的配置文件,即报警规则,用于全局的,邮件的发送端与接收端。而后再将alertmanager的ConfigMap文件,添加到生成Prometheus服务即配置文件的yaml文件当中,重新创建
[root@master01 prometheus]#vim alertmanager-cm.yaml
[root@master01 prometheus]#cat alertmanager-cm.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager
namespace: monitor-sa
data:
alertmanager.yml: |-
global: #设置发件人邮箱信息
resolve_timeout: 1m #告警被标记为已解决之前等待的时间
smtp_smarthost: 'smtp.qq.com:25' #SMTP 服务器地址和端口,用于发送电子邮件
smtp_from: '1234567890@qq.com' #发送电子邮件时使用的发件人地址
smtp_auth_username: '123456789@qq.com' #SMTP 认证的用户名
smtp_auth_password: 'ygljeciudfinbchf' #SMTP 认证的密码,为QQ邮箱的授权码
smtp_require_tls: false #关闭TLS连接
route: #告警路由配置
group_by: [alertname] #用于分组告警的字段列表
group_wait: 10s #等待10s来合并新的告警,以便将它们一起发送
group_interval: 10s #发送一组新的告警后,等待10s来合并新的告警
repeat_interval: 10m #尚未解决的告警,重新发送通知的间隔时间
receiver: default-receiver #默认的接收者名称
receivers: #接收者列表信息
- name: 'default-receiver' #接收者的名称与上述一致
email_configs: #电子邮件接收者配置
- to: '987654321@139.com' #接收告警通知的电子邮件地址
send_resolved: true #当告警被标记为已解决时,发送通知
[root@master01 prometheus]#kubectl apply -f alertmanager-cm.yaml
configmap/alertmanager created
[root@master01 prometheus]#kubectl get configmaps alertmanager -n monitor-sa
NAME DATA AGE
alertmanager 1 16s
2.创建prometheus和告警规则配置文件
[root@master01 prometheus]#cat prometheus-alertmanager-cfg.yaml
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitor-sa
data:
prometheus.yml: |
rule_files:
- "rules.yml"
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
- job_name: 'kubernetes-schedule'
scrape_interval: 5s
static_configs:
- targets: ['192.168.83.30:10251'] #masterIP地址的kubernetes-controlle端口
- job_name: 'kubernetes-controller-manager'
scrape_interval: 5s
static_configs:
- targets: ['192.168.83.30:10252'] #masterIP地址的kubernetes-controlle端口
- job_name: 'kubernetes-kube-proxy'
scrape_interval: 5s
static_configs:
- targets: ['192.168.83.30:10249','192.168.83.40:10249','192.168.83.50:10249']
#所有节点的kube-proxy端口
- job_name: 'kubernetes-etcd'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crt
cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crt
key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.key
scrape_interval: 5s
static_configs:
- targets: ['192.168.83.30:2379']
rules.yml: |
groups:
- name: example
rules:
- alert: kube-proxy的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: kube-proxy的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: scheduler的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: scheduler的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: controller-manager的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: controller-manager的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 0
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: apiserver的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: apiserver的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: etcd的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: etcd的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: kube-state-metrics的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"
value: "{{ $value }}%"
threshold: "80%"
- alert: kube-state-metrics的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"
value: "{{ $value }}%"
threshold: "90%"
- alert: coredns的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"
value: "{{ $value }}%"
threshold: "80%"
- alert: coredns的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"
value: "{{ $value }}%"
threshold: "90%"
- alert: kube-proxy打开句柄数>600
expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kube-proxy打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-schedule打开句柄数>600
expr: process_open_fds{job=~"kubernetes-schedule"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-schedule打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-schedule"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-controller-manager打开句柄数>600
expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-controller-manager打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-apiserver打开句柄数>600
expr: process_open_fds{job=~"kubernetes-apiserver"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-apiserver打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-etcd打开句柄数>600
expr: process_open_fds{job=~"kubernetes-etcd"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-etcd打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-etcd"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: coredns
expr: process_open_fds{k8s_app=~"kube-dns"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600"
value: "{{ $value }}"
- alert: coredns
expr: process_open_fds{k8s_app=~"kube-dns"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000"
value: "{{ $value }}"
- alert: kube-proxy
expr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: scheduler
expr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kubernetes-controller-manager
expr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kubernetes-apiserver
expr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kubernetes-etcd
expr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kube-dns
expr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: HttpRequestsAvg
expr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000"
value: "{{ $value }}"
threshold: "1000"
- alert: Pod_restarts
expr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0
for: 2s
labels:
severity: warnning
annotations:
description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的"
value: "{{ $value }}"
threshold: "0"
- alert: Pod_waiting
expr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中"
value: "{{ $value }}"
threshold: "1"
- alert: Pod_terminated
expr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除"
value: "{{ $value }}"
threshold: "1"
- alert: Etcd_leader
expr: etcd_server_has_leader{job="kubernetes-etcd"} == 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_leader_changes
expr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_failed
expr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_db_total_size
expr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G"
value: "{{ $value }}"
threshold: "10G"
- alert: Endpoint_ready
expr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用"
value: "{{ $value }}"
threshold: "1"
- name: 物理节点状态-监控告警
rules:
- alert: 物理节点cpu使用率
expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90
for: 2s
labels:
severity: ccritical
annotations:
summary: "{{ $labels.instance }}cpu使用率过高"
description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理"
- alert: 物理节点内存使用率
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90
for: 2s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}内存使用率过高"
description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理"
- alert: InstanceDown
expr: up == 0
for: 2s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}: 服务器宕机"
description: "{{ $labels.instance }}: 服务器延时超过2分钟"
- alert: 物理节点磁盘的IO性能
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"
description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"
- alert: 入网流量带宽
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流入网络带宽过高!"
description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"
- alert: 出网流量带宽
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流出网络带宽过高!"
description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"
- alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"
description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"
description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
删除之前的配置,更新配置
[root@master01 prometheus]#kubectl delete -f prometheus-cfg.yaml
configmap "prometheus-config" deleted
[root@master01 prometheus]#kubectl get configmaps -n monitor-sa
NAME DATA AGE
alertmanager 1 10m
kube-root-ca.crt 1 47h
[root@master01 prometheus]#kubectl apply -f prometheus-alertmanager-cfg.yaml
configmap/prometheus-config created
[root@master01 prometheus]#kubectl get configmaps -n monitor-sa
NAME DATA AGE
alertmanager 1 10m
kube-root-ca.crt 1 47h
prometheus-config 2 3s
3.安装prometheus和alertmanager
3.1 创建secret资源
生成一个 secret 资源 etcd-certs,这个在部署 prometheus 需要,用于监控 etcd 相关资
[root@master01 prometheus]#kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
secret/etcd-certs created
[root@master01 prometheus]#kubectl get secret etcd-certs -n monitor-sa
NAME TYPE DATA AGE
etcd-certs Opaque 3 33s3.2 创建资源清单
更新资源清单 yaml 文件,安装 prometheus 和 alertmanage
[root@master01 prometheus]#cat prometheus-alertmanager-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitor-sa
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false'
spec:
nodeName: node01
serviceAccountName: monitor
containers:
- name: prometheus
image: prom/prometheus:v2.2.1
imagePullPolicy: IfNotPresent
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=24h"
- "--web.enable-lifecycle"
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus
name: prometheus-config
- mountPath: /prometheus/
name: prometheus-storage-volume
- name: k8s-certs
mountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/
- name: localtime
mountPath: /etc/localtime
- name: alertmanager
image: prom/alertmanager:v0.14.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/alertmanager.yml"
- "--log.level=debug"
ports:
- containerPort: 9093
protocol: TCP
name: alertmanager
volumeMounts:
- name: alertmanager-config
mountPath: /etc/alertmanager
- name: alertmanager-storage
mountPath: /alertmanager
- name: localtime
mountPath: /etc/localtime
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
- name: prometheus-storage-volume
hostPath:
path: /data
type: Directory
- name: k8s-certs
secret:
secretName: etcd-certs
- name: alertmanager-config
configMap:
name: alertmanager
- name: alertmanager-storage
hostPath:
path: /data/alertmanager
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai创建资源
[root@master01 prometheus]#kubectl delete -f prometheus-deploy.yaml
deployment.apps "prometheus-server" deleted
[root@master01 prometheus]#kubectl apply -f prometheus-alertmanager-deploy.yaml
deployment.apps/prometheus-server created
[root@master01 prometheus]#kubectl get pod prometheus-server-6dcf7665cc-g95ld -n monitor-sa
NAME READY STATUS RESTARTS AGE
prometheus-server-6dcf7665cc-g95ld 2/2 Running 0 19s(三)部署alertmanager的service
[root@master01 prometheus]#cat alertmanager-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
name: prometheus
kubernetes.io/cluster-service: 'true'
name: alertmanager
namespace: monitor-sa
spec:
ports:
- name: alertmanager
nodePort: 30066
port: 9093
protocol: TCP
targetPort: 9093
selector:
app: prometheus
sessionAffinity: None
type: NodePort
[root@master01 prometheus]#kubectl apply -f alertmanager-svc.yaml
service/alertmanager created
[root@master01 prometheus]#kubectl get svc alertmanager -n monitor-sa
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager NodePort 10.96.181.208 <none> 9093:30066/TCP 13s(四)访问alertmanager
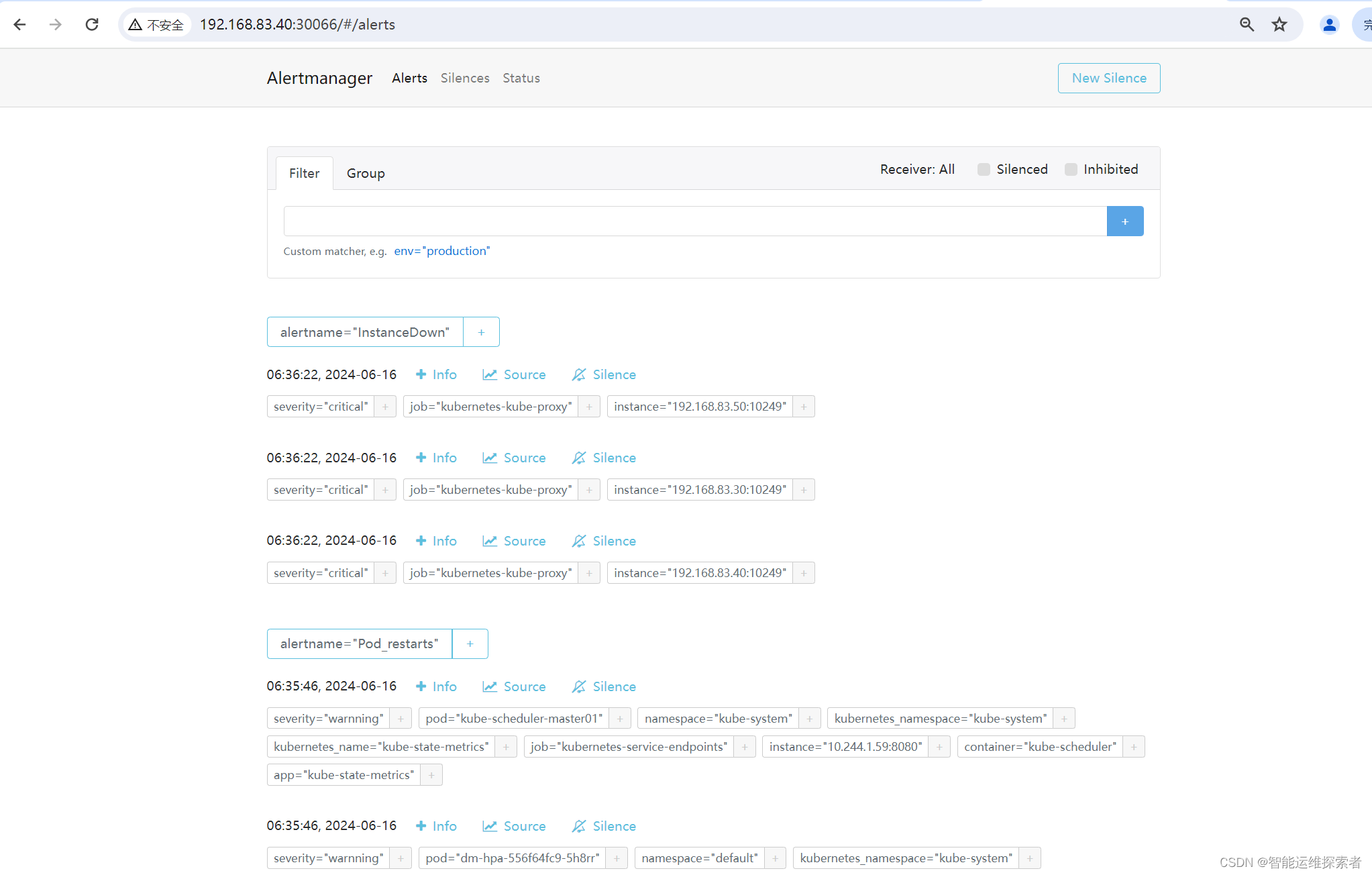
浏览器访问 http://192.168.83.40:30066/#/alerts ,登陆 alertmanager
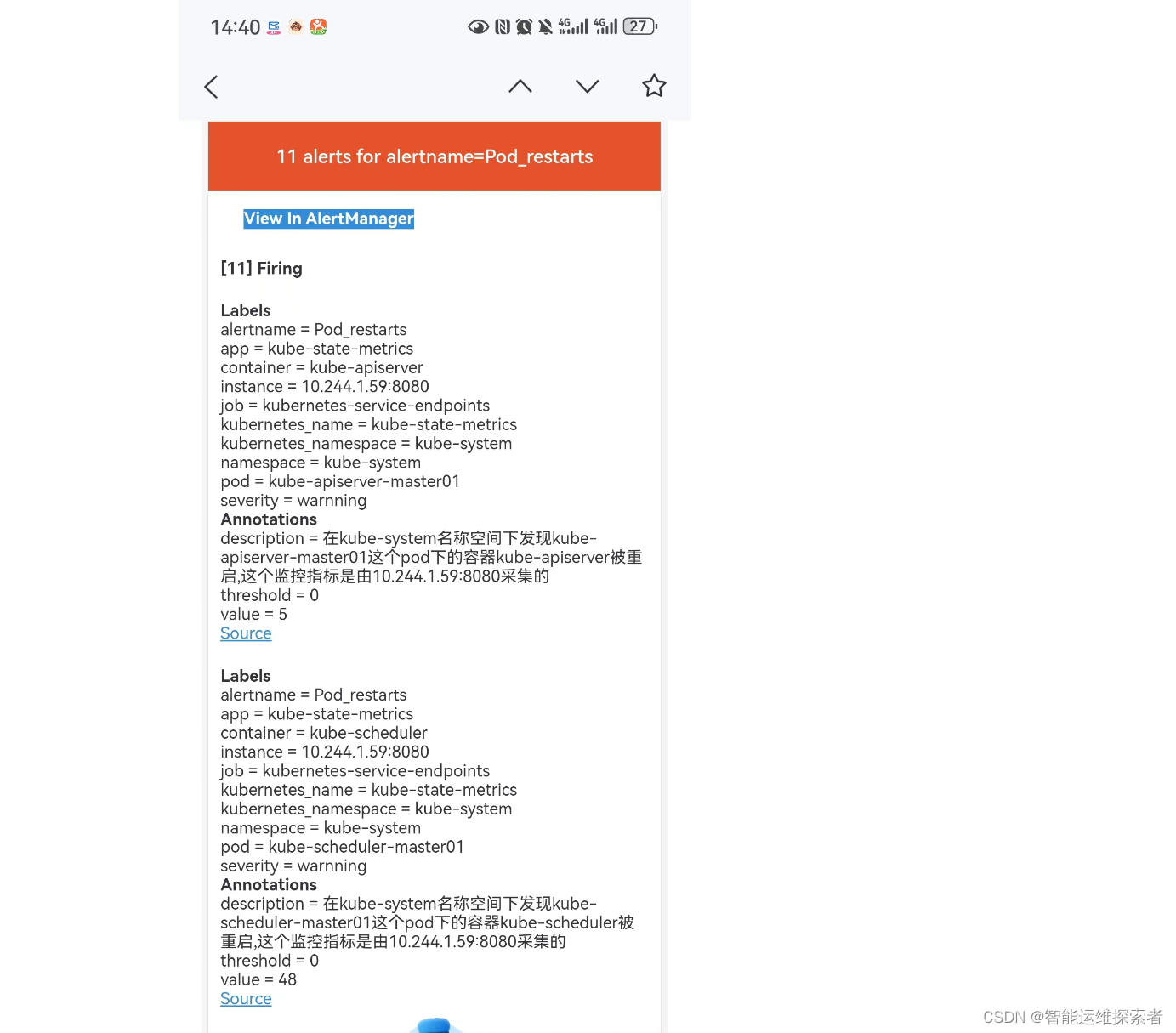
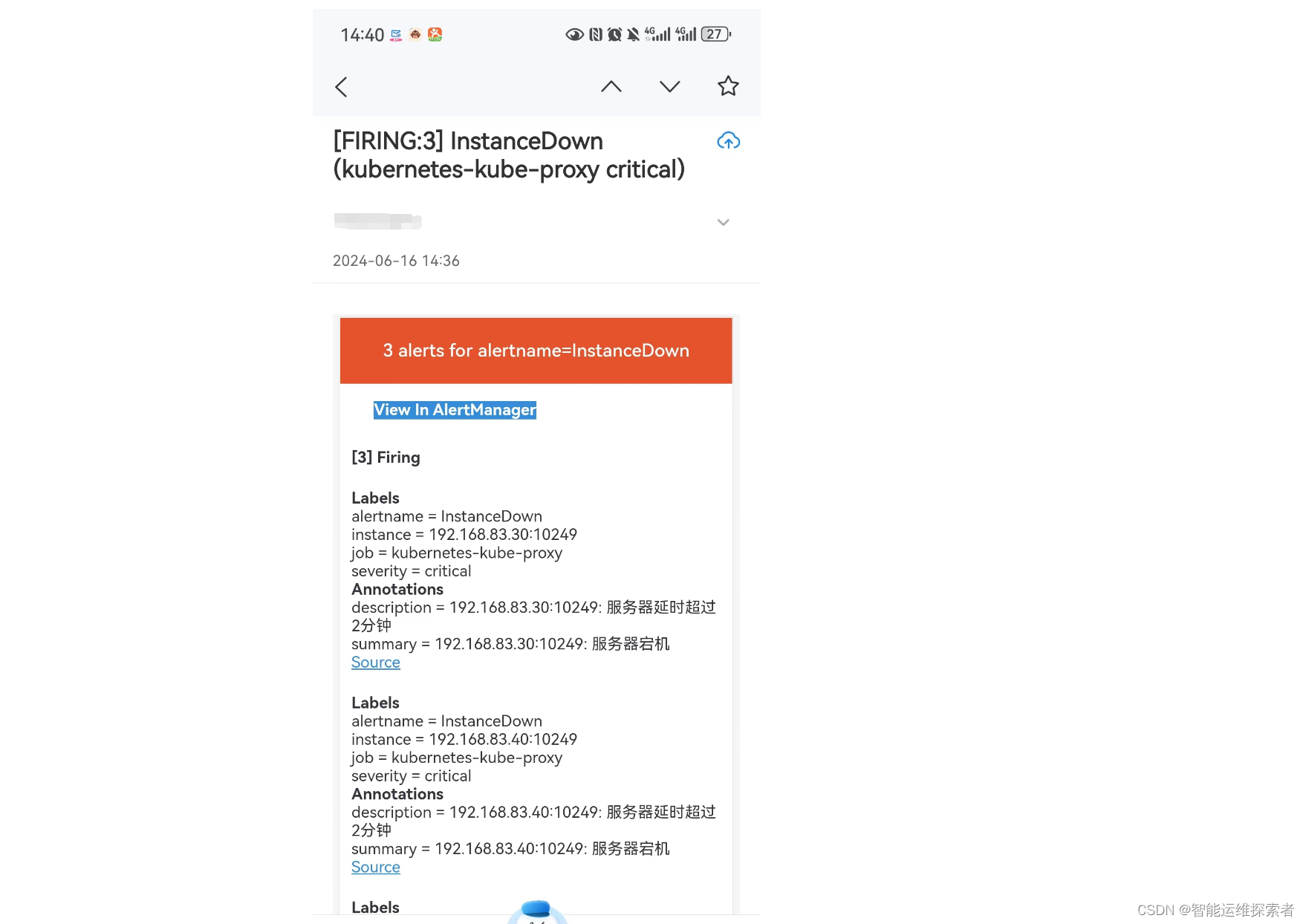
查看接收到的邮件报警,可以发现与 alertmanager 显示的告警一致
(五)处理kube-proxy监控告警
因为 kube-proxy 默认端口10249是监听在 127.0.0.1 上的,需要改成监听到物理节点上
原先的监听地址
[root@master01 prometheus]#ss -natp |grep 10249
LISTEN 0 128 127.0.0.1:10249 *:* users:(("kube-proxy",pid=3966,fd=14))
修改kube-proxy监控地址
[root@master01 prometheus]#kubectl edit configmap kube-proxy -n kube-system
......
kind: KubeProxyConfiguration
metricsBindAddress: "0.0.0.0:10249"
mode: ipvs
......
重新启动kube-proxy
[root@master01 prometheus]#kubectl get pods -n kube-system | grep kube-proxy |awk '{print $1}' | xargs kubectl delete pods -n kube-system
pod "kube-proxy-psdnv" deleted
pod "kube-proxy-zmh82" deleted
pod "kube-proxy-zwnx2" deleted
#删除之后daemonsets控制器会在每个节点上重新创建一个
[root@master01 prometheus]#kubectl get daemonsets.apps -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-proxy 3 3 3 3 3 kubernetes.io/os=linux 30d
//在节点进行查看
[root@master01 prometheus]#ss -natp |grep 10249
LISTEN 0 128 :::10249 :::* users:(("kube-proxy",pid=68880,fd=14)alert 查看
点击 prometheus 页面的 Alerts,点开一个告警项,FIRING 表示 prometheus 已经将告警发给alertmanager,在 Alertmanager 中可以看到有一个alert。登录到浏览器访问 http://192.168.83.40:30066/#/alerts ,登陆alertmanager即可看到

邮箱查看
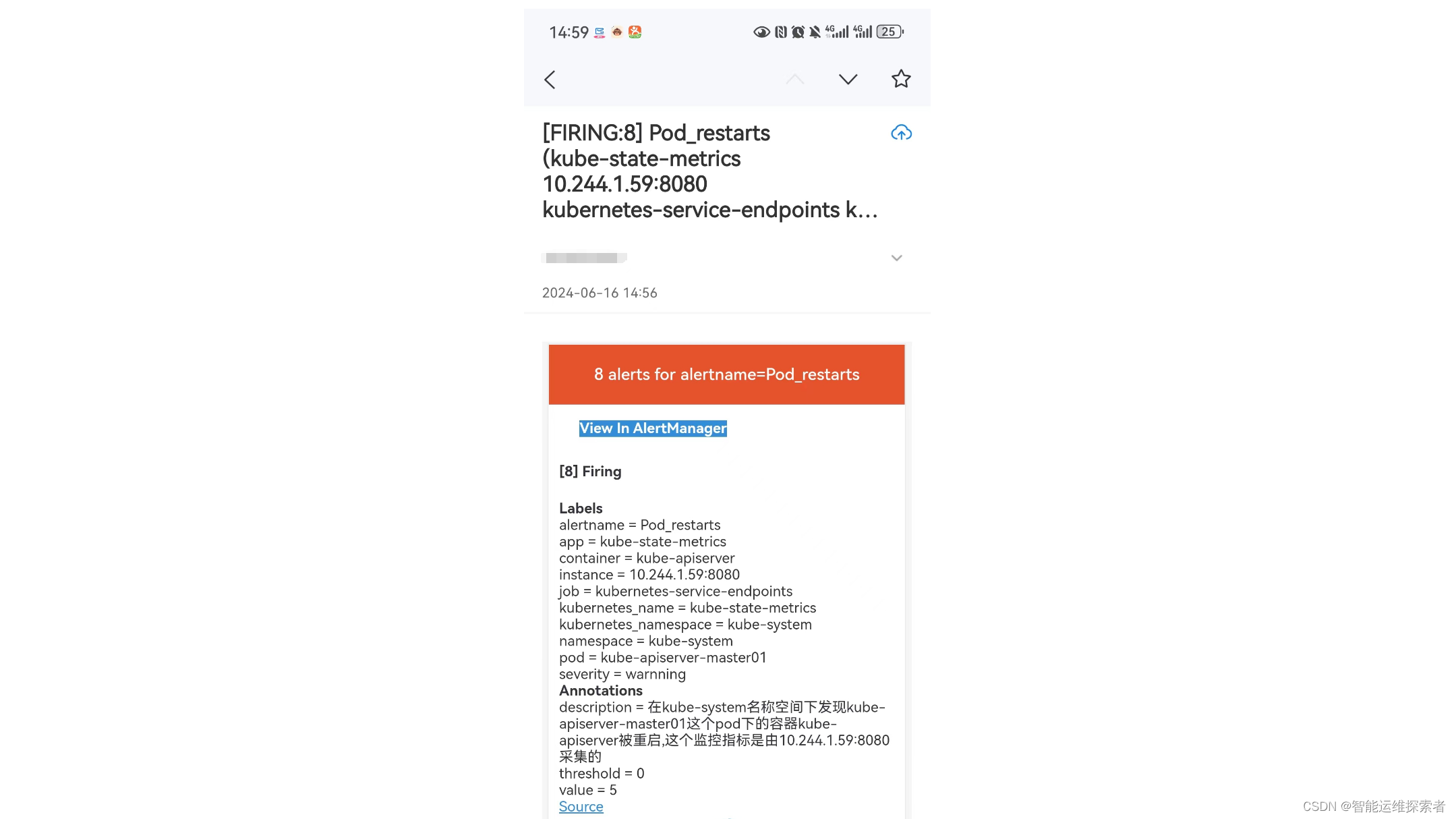
告警信息一致









![[DDR4] DDR4 相对 DDR3差异与优势](https://img-blog.csdnimg.cn/direct/8d31fad7a28745eb81e253606f226423.png#pic_center)